Estatística amostral
Este módulo permite calcular parâmetros de amostragem simples e estratificada com base nos volumes das unidades amostrais.
Parâmetros da Classe
SamplingStats(volume_df)
| Parâmetros | Descrição |
|---|---|
| volume_df | O dataframe contendo os dados de volume por unidade amostral. |
Métodos da Classe
SamplingStats.simple(total_area, plot_id, plot_area,
volume, error_lim=10, conf=95)#(1)!
SamplingStats.stratified(total_area, stratum_id, stratum_area,
plot_id, plot_area, volume, error_lim=10, conf=95)#(2)!
SamplingStats.stratified_anova()
-
total_area = Nome da coluna que contém o valor da área total em metros quadrados do povoamento florestal avaliado.
plot_id = Nome da coluna que contém o identificador único da parcela/unidade amostral.
plot_area = Nome da coluna que contém a área em metros quadrados da parcela/unidade amostral.
volume = Nome da coluna que contém os valores de volume em metros cúbicos de cada parcela/unidade amostral.
error_lim = (Opcional) Valor númerico ou nome da coluna que contenha o limite de erro tolerado em valor percentual.
conf = (opcional) Valor numérico ou nome da coluna que representa o nível de confiança (por exemplo, 95%) a ser utilizado nos cálculos estatísticos. -
total_area = Nome da coluna que contém o valor da área total em metros quadrados do povoamento florestal avaliado.
stratum_id = Nome da coluna que contém o identificador único do estrato.
plot_id = Nome da coluna que contém o identificador único da parcela/unidade amostral.
plot_area = Nome da coluna que contém a área em metros quadrados da parcela/unidade amostral.
volume = Nome da coluna que contém os valores de volume em metros cúbicos de cada parcela/unidade amostral.
error_lim = (Opcional) Valor númerico ou nome da coluna que contenha o limite de erro tolerado em valor percentual.
conf = (opcional) Valor numérico ou nome da coluna que representa o nível de confiança (por exemplo, 95%) a ser utilizado nos cálculos estatísticos.
| Parâmetros | Descrição |
|---|---|
| .simple() | Retorna um DataFrame contendo os parâmetros estatísticos e a suficiência amostral para amostragem aleatória simples. |
| .stratified() | Retorna um DataFrame contendo os parâmetros estatísticos e a suficiência amostral para amostragem estratificada. |
| .stratified_anova() | Retorna um DataFrame contendo análise de variância (ANOVA) da estratificação realizada com o método .stratified(). |
Amostragem simples
Exemplo de Uso
Considere a adaptação do exemplo utilizado por Sanquetta et al. (2014) para exemplificar o cálculo das estatísticas do processo de amostragem aleatória simples.
| Fazenda | Parcela | area_total (m²) | area_parcela (m²) | Volume (m³) | limite_erro(%) | nivel_confianca(%) |
|---|---|---|---|---|---|---|
| Fazenda 1 | 1 | 400000 | 600 | 20,85 | 10 | 95 |
| Fazenda 1 | 2 | 400000 | 600 | 19,47 | 10 | 95 |
| Fazenda 1 | 3 | 400000 | 600 | 24,13 | 10 | 95 |
| Fazenda 1 | 4 | 400000 | 600 | 24,34 | 10 | 95 |
| Fazenda 1 | 5 | 400000 | 600 | 25,13 | 10 | 95 |
| Fazenda 1 | 6 | 400000 | 600 | 22,37 | 10 | 95 |
| Fazenda 1 | 7 | 400000 | 600 | 22,51 | 10 | 95 |
| Fazenda 1 | 8 | 400000 | 600 | 19,78 | 10 | 95 |
| Fazenda 1 | 9 | 400000 | 600 | 25,05 | 10 | 95 |
| Fazenda 1 | 10 | 400000 | 600 | 28,84 | 10 | 95 |
| Fazenda 1 | 11 | 400000 | 600 | 23,70 | 10 | 95 |
| Fazenda 1 | 12 | 400000 | 600 | 24,78 | 10 | 95 |
| Fazenda 1 | 13 | 400000 | 600 | 22,58 | 10 | 95 |
| Fazenda 1 | 14 | 400000 | 600 | 23,70 | 10 | 95 |
| Fazenda 1 | 15 | 400000 | 600 | 36,16 | 10 | 95 |
| Fazenda 1 | 16 | 400000 | 600 | 17,83 | 10 | 95 |
| sampling_stats_simple_example.py | |
|---|---|
- Importa a classe
SamplingStats. - Importa o
pandaspara manipulação de dados.
- Carrega arquivo xlsx contendo os dados.
- Cria a variável
sscontendo a classeSamplingStatse recebendo o DataFramedf. - Indica o nome das colunas para cada parâmetro da função
.simple()e salve os resultados na variávelss_result. - Salva os resultados em um arquivo
simple_sampling_stats.xlspara posterior visualização.
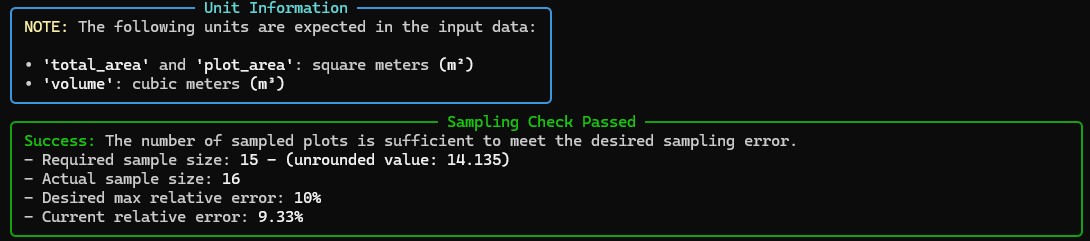
As seguintes informações serão geradas pela função simple()
| metric | value |
|---|---|
| population | finite |
| real_n_par | 16 |
| ideal_n_par | 15 |
| mean_stratified (m³/plot) | 23,83 |
| variance (m³/plot) | 17,82 |
| st_deviation (m³/plot) | 4,22 |
| coeff_variation (%) | 17,72 |
| variance_of_the_mean (m³/plot) | 1,09 |
| st_error_of_the_mean (m³/plot) | 1,04 |
| abs_sampl_error (m³/plot) | 2,24 |
| rel_sampl_error (%) | 9,39 |
| mean_confidence_interval (m³) | (21,59, 26,06) |
| confidence_interval_total population (m³) | (14400,52, 17383,7) |
| total (m³/ha) | 397,3 |
| total_population (m³) | 15892,11 |
Amostragem estratificada
Exemplo de Uso
| sampling_stats_stratified_example.py | |
|---|---|
- Importa a classe
SamplingStats. - Importa o
pandaspara manipulação de dados.
- Carrega o arquivo xlsx contendo os dados.
- Cria a variável
sscontendo a classeSamplingStatse recebendo o DataFramedf_stratified. - Indica o nome das colunas para cada parâmetro da função
.stratified()e salve os resultados na variávelss_result. - Salva os resultados em um arquivo
stratified_sampling_stats.xlsxpara posterior visualização. - Salva os valores da análise de variância na variável
anova. - Salva a análise de variância em um arquivo
anova.xlsx
Para esse exemplo, também usaremos os valores obtidos em Sanquetta et al. (2014).
Fazer download do arquivo.
As seguintes informações serão geradas pela função stratified(). Nesse caso, são gerados os resumos estatísticos tanto para o total quanto para os estratos individuais.
| metrics | total | Estrato 1 | Estrato 2 |
|---|---|---|---|
| population | finite | finite | finite |
| real_n_par | 24 | 12 | 12 |
| ideal_n_par | 8 | 5,2 | 2,8 |
| mean (m³/plot) | 107,25 | 89,08 | 125,42 |
| variance (m³/plot) | 137,91 | 71,54 | 261,17 |
| st_deviation (m³/plot) | 11,15 | 8,46 | 16,16 |
| coeff_variation (%) | 10,4 | 9,49 | 12,89 |
| variance_of_the_mean (m³/plot) | 5,05 | 5,85 | 21,02 |
| st_error_of_the_mean (m³/plot) | 2,25 | 2,42 | 4,58 |
| abs_sampl_error (m³) | 5,5 | 5,92 | 11,22 |
| rel_sampl_error (%) | 5,13 | 6,64 | 8,94 |
| mean_confidence_interval (m³) | (101,75, 112,75) | (83,16, 95,0) | (114,2, 136,63) |
| confidence_interval_total population (m³) | (101752,9, 112747,1) | (54056,81, 61751,53) | (39969,52, 47822,15) |
| total (m³/ha) | 107,25 | 89,08 | 125,42 |
| total_population (m³) | 107250 | 57904,17 | 43895,83 |
Análise de variância (ANOVA) gerada:
| Fonte de Variação | SQ | gl | QM | F | F_crítico | H₀ |
|---|---|---|---|---|---|---|
| Entre Estratos | 8.633,527 | 1,000 | 8.633,527 | 51,898 | 4,301 | Rejeitada |
| Dentro dos Estratos | 3.659,833 | 22,000 | 166,356 | |||
| Total | 12.293,360 | 23,000 |
Equações utilizadas
Intensidade amostral
Populações finitas
Populações infinitas
Estatísticas
Intensidade amostral
Populações finitas
Populações infinitas
Estatísticas
Análise de variância
Notação
- \( N \): Número total de unidades da população ou número potencial
- \( n \): Número de unidades amostradas ou medidas
- \( n_h \): Número de unidades amostradas ou medidas no estrato
- \( t\): Valor da distribuição t de Student
- \( s_x^2 \): Variância
- \( s_h^2 \): Variância do estrato h
- \( s_{\bar{x}(st)} \): Erro padrão da média do estrato
- \( W_h \): Proporção do estrato h na população
- \( E \): Limite do erro tolerado (%)
- \( \bar{x} \): Média amostral
- \( \bar{x}_h \): Média amostral do estrato
- \( x_{ih} \): volume da i-ésima parcela dentro do estrato h
Referências
SANQUETTA, C. R.; CORTE, A. P. D.; RODRIGUES, A. L.; WATZLAWICK, L. F. (2014). Inventários florestais: planejamento e execução. Curitiba: Multi-Graphic, 406 p.