Estratificador
Com este módulo, você poderá obter assistência no processo de estratificação de seus plantios florestais. Utilize dados de inventário florestal para estratificar automaticamente as plantações, selecionando as variáveis florestais que considera mais relevantes e utilizando um número pré-definido de estratos ou permitindo que o módulo determine o número ideal de estratos.
Estratificação Florestal com Python
O processo de estratificação florestal requer o conhecimento de diversos fatores:
- Localização geográfica
- Espécie florestal
- Tipo de solo
- Idade do povoamento
- Finalidade dos produtos
- Histórico de manejo
Nesse contexto, o módulo Python desenvolvido para estratificação surge como uma ferramenta de apoio ao planejamento florestal, oferecendo uma visão inicial orientada por dados quantitativos.
Funções Principais
O módulo inclui funções como:
stratify_kmeansstratify_hierarchical
Essas funções utilizam algoritmos de agrupamento multivariado (k-means e hierárquico, respectivamente) para identificar padrões em variáveis contínuas, como:
- Diâmetro médio
- Altura média
- Volume por hectare
- Idade
- Índice de sítio
Os algoritmos agrupam as unidades amostrais em estratos homogêneos, que podem ser utilizados para:
- Inventário florestal
- Alocação amostral
- Otimização do manejo
Importante
Os resultados não substituem a interpretação técnica especializada, mas fornecem uma base objetiva para análise exploratória, facilitando a tomada de decisão em projetos florestais.
Parâmetros da Classe
Estratificador
Stratifier(df, y, *train_columns, iterator=None)
| Parâmetros | Descrição |
|---|---|
| df | O dataframe contendo os dados do inventário florestal. |
| *groups_columns | Colunas que serão utilizadas para a estratificação. Apenas numéricas. |
| iterator | (Opcional) A estratificação será realizada para cada iterator. |
Métodos da Classe
Stratifier.stratify_kmeans(k=None, k_method=None, max_k=100,
show_plots=True, save_plots_dir=None)#(1)!
Stratifier.stratify_hierarchical(k=None, k_method=None, max_k=10,
show_plots=True, save_plots_dir=None)#(2)!
-
k = (Opcional) Número desejado de estratos.
k_method = (Opcional) Casoknão seja especificado, define qual método será usado para determinar o número de estratos. Opções:elbow,silhouette,davies_bouldin,calinski_harabasz.Padrão = "elbow".
max_k = (Opcional) Número máximo de estratos a serem criados.
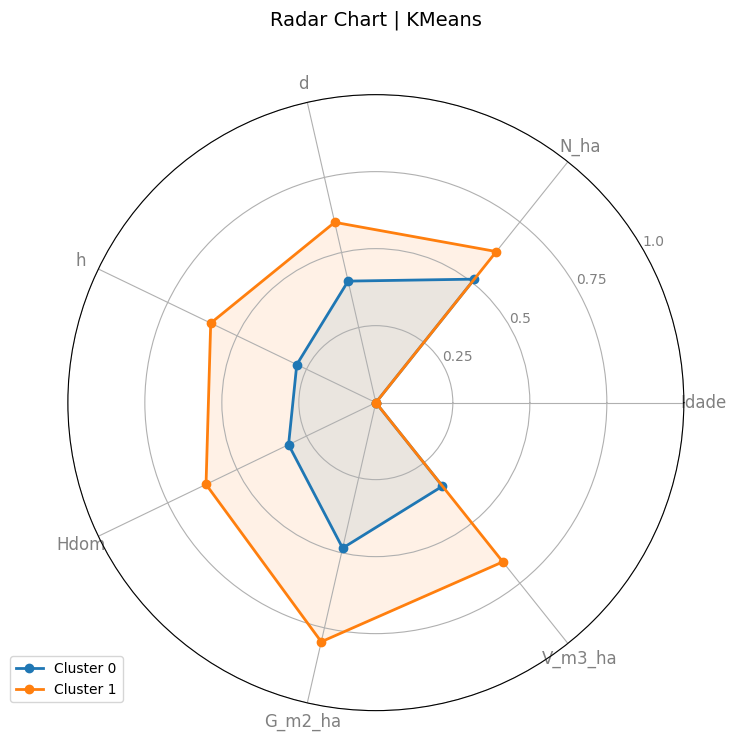
show_plots = Setrue, exibe o gráfico de radar com os estratos gerados.
save_plot_dir = (Opcional) Diretório para salvar os gráficos dos estratos gerados. -
k = (Opcional) Número desejado de estratos.
k_method = (Opcional) Casoknão seja especificado, define qual método será usado para determinar o número de estratos. Opções:elbow,silhouette,davies_bouldin,calinski_harabasz.Padrão = "elbow".
max_k = (Opcional) Número máximo de estratos a serem criados.
show_plots = Setrue, exibe o gráfico de radar com os estratos gerados.
save_plot_dir = (Opcional) Diretório para salvar os gráficos dos estratos gerados.
| Métodos | Descrição |
|---|---|
| .stratify_kmeans() | Realiza a estratificação utilizando o algoritmo K-Means. |
| .stratify_hierarchical() | Realiza a estratificação utilizando o algoritmo Agglomerative Clustering. |
Importante
Quando a variável k não for definida, o algoritmo tentará determinar automaticamente o número ideal de estratos utilizando o método elbow como padrão.
Para selecionar outro método de definição automática de k, basta informar o parâmetro method com o nome do método desejado. Os métodos disponíveis são:
elbow: Baseado na análise da inércia para diferentes valores dek. Utiliza a segunda derivada para identificar o ponto de inflexão.silhouette: Utiliza o coeficiente de silhueta para avaliar a separação entre os grupos. Maior valor indica melhor agrupamento.davies_bouldin: Avalia a compacidade e separação dos grupos. Quanto menor o índice, melhor o agrupamento.calinski_harabasz: Utiliza a razão entre dispersão entre grupos e dispersão intra-grupo. Quanto maior o índice, melhor o agrupamento.
Cada método adapta-se melhor a diferentes características dos dados. A escolha correta pode melhorar significativamente a qualidade dos estratos gerados.
De mesmo modo, o usuário pode limitar o número máximo de estratos por meio da variável max_k, que define o maior valor de k a ser considerado durante o processo de avaliação automática.
Exemplo de Uso
Como exemplo, iremos usar uma adaptação dos dados obtidos por Arce e Dobner Jr. (2024) para Eucalyptus dunnii. A base de dados é composta por 81 parcelas de 300m², com idade igual a 7 anos.
- Importa a classe
Stratifier. - Importa o
pandaspara manipulação de dados.
| stratifier_example.py | |
|---|---|
- Carrega seu arquivo
xlsxcontendo os dados do inventário. - Cria uma lista chamada
columns_to_checkcontendo as colunas que serão utilizadas para a estratificação. - Cria a variável
stutilizando o dataframedf, passando as colunascolumns_to_checkcomo parâmetros de estratificação. Como - Realiza a estratificação utilizando o algoritmo "KMeans", permitindo que o algoritmo determine o número de estratos. Salva os resultados na variável
stratified_df. Salva o gráfico de radar gerado no diretório informado.
Saídas
Tabelas
stratified_df (1)
- DataFrame inicial com uma coluna a mais chamada
Cluster, que contém o número do cluster que aquela linha de dados foi enquadrada, variando de 0 an.
| Chave_Parcela | Idade | N_ha | d | h | Hdom | G_m2_ha | V_m3_ha | S | Cluster |
|---|---|---|---|---|---|---|---|---|---|
| 14401109002_P1 | 7 | 866,67 | 16,63 | 16,09 | 16,50 | 19,43 | 112,77 | 15,44 | 0 |
| 14401109003_P2 | 7 | 866,67 | 16,55 | 15,02 | 16,47 | 19,91 | 110,36 | 15,17 | 0 |
| 14401110009_P3 | 7 | 600,00 | 16,96 | 14,07 | 15,32 | 13,92 | 64,83 | 14,71 | 0 |
| 1440817_P3 | 7 | 1066,67 | 16,45 | 14,53 | 16,49 | 24,24 | 129,46 | 14,61 | 0 |
| 1440818_P6 | 7 | 833,33 | 17,27 | 14,62 | 16,00 | 20,79 | 112,73 | 12,64 | 0 |
Gráficos
Referências
ARCE, JULIO EDUARDO; DOBNER JR., MARIO. (2024). Manejo e planejamento de florestas plantadas: com ênfase nos gêneros Pinus e Eucalyptus. Curitiba, PR: Ed. dos Autores, 419p.
KARCZMAREK, Pawel; KIERSZTYN, Adam; PEDRYCZ, Witold; AL, Ebru. K-Means-based isolation forest. Knowledge-Based Systems, Amsterdam, v. 195, p. 105659, 11 maio 2020. Disponível em: https://doi.org/10.1016/j.knosys.2020.105659. Acesso em: 22 maio 2025.
DETRINIDAD, E.; LÓPEZ-RUIZ, Víctor-Raúl. The Interplay of Happiness and Sustainability: A Multidimensional Scaling and K-Means Cluster Approach. Sustainability, v. 16, n. 22, p. 10068–10068, 19 nov. 2024.
MÄRZINGER, T.; KOTÍK, J.; PFEIFER, C. Application of Hierarchical Agglomerative Clustering (HAC) for Systemic Classification of Pop-Up Housing (PUH) Environments. Applied Sciences, v. 11, n. 23, p. 11122, 24 nov. 2021.